Benchmarking AI Agents for Vulnerability Detection: How Well Do LLMs Spot Security Flaws?

Source: Benchmarking LLM agents for vulnerability research - FuzzingLabs
AI-driven tools show promise in enhancing vulnerability research and securing software. To explore this potential, FuzzingLabs ran experiments assessing various large language models (LLMs) on their ability to identify vulnerabilities in vulnerable Python, Go, and C++ codebases.
How the AI Agents Were Tested
Instead of deploying complex multi-agent systems, the study focused on single-pass vulnerability detection by scanning source code chunks using LLMs. The process included:
- Breaking source files into manageable chunks
- Analyzing code line-by-line looking for specific vulnerability types:
- SQL Injection (CWE-89)
- Cross-Site Scripting (XSS, CWE-79)
- Command Injection (CWE-77)
- Weak Cryptography (CWE-327)
- Buffer Overflow (CWE-120)
- File Inclusion (CWE-98)
- Comparing found issues to the known list of vulnerabilities (ground truth)
Each detected vulnerability was evaluated based on its file location, exact vulnerable line, and CWE classification.
Experiment Results
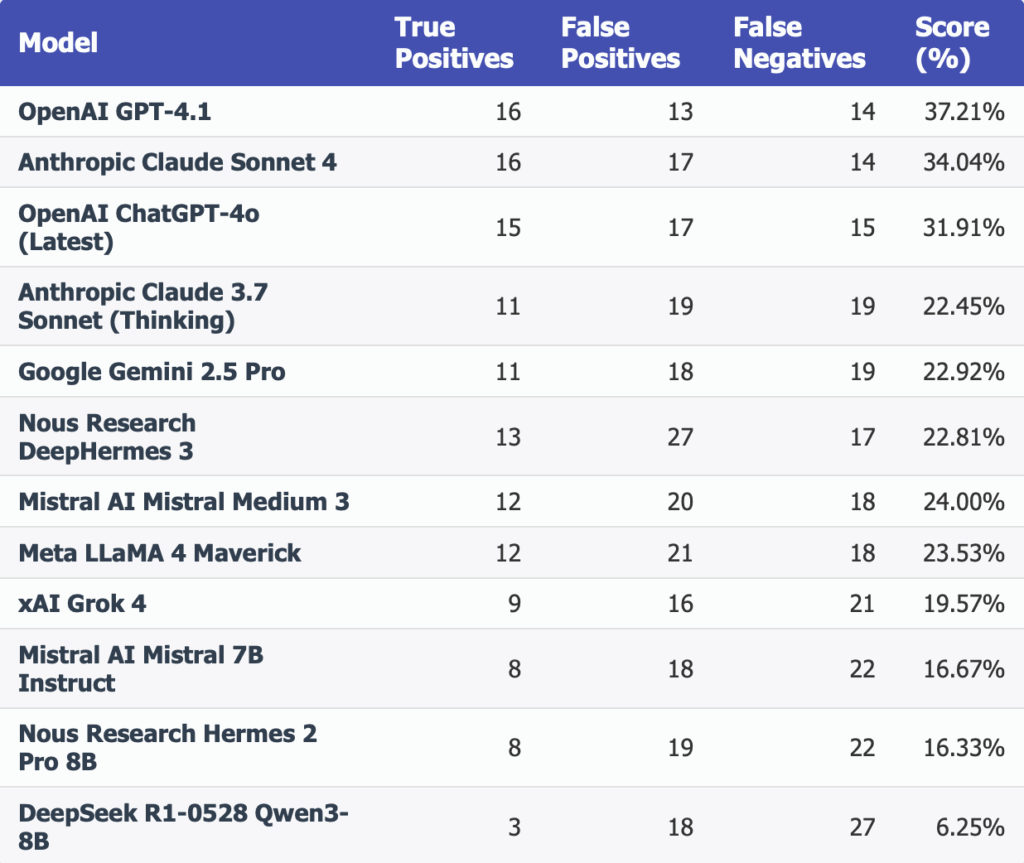
The following metrics were measured per model:
- True Positives (TP)
- False Positives (FP)
- False Negatives (FN)
- Final Score = TP / (TP + FP + FN)
Key Takeaways
Proprietary Models Lead in Accuracy
- OpenAI GPT-4.1 (37.21%),
- Anthropic Claude Sonnet 4 (34.04%),
- OpenAI ChatGPT-4o (31.91%)
These models, trained with reinforcement learning and human feedback (RLHF), top the leaderboard for zero-shot vulnerability spotting.
Effective Mid-Tier Competitors
- Mistral Medium 3 (24.00%)
- Meta LLaMA 4 Maverick (23.53%)
These models prove targeted training and high-quality datasets can drive solid security analysis without being the largest models.
Strong Showing from Open-Community Projects
- NousResearch DeepHermes 3 (22.81%)
- Hermes 2 Pro 8B (16.33%)
Community-driven efforts deliver competitive results, demonstrating valuable open-source innovation in code security.
Accuracy Challenges Persist
- Best models detect under 40% of true positives, highlighting the limitations of single-shot, zero-shot prompts for thorough vulnerability analysis.
Models Tend to Overreport Risks
- False positives range between 13 to 27, showing these AI agents flag many possible issues but often fail to distinguish harmless code, emphasizing the need for human review.
Training Quality Outweighs Model Size
- While largest proprietary models perform better, careful instruction tuning and quality data emerge as more critical than just scaling model parameters.
Room to Grow Through Engineering
- This study employed a straightforward setup - directly feeding prompts to LLMs without advanced coordination or iterative workflows.
- Future improvements could stem from multi-agent cooperation, dynamic prompting, and repeated code reviews, likely boosting vulnerability detection much beyond this baseline.
About FuzzingLabs
Founded in Paris in 2021, FuzzingLabs specializes in cybersecurity research focused on fuzz testing, vulnerability detection, and blockchain security. They combine academic insight and practical experience to secure blockchain infrastructures critical to Web3.
For audits or collaborations, reach out to contact@fuzzinglabs.com.
Stay Updated with FuzzingLabs
- Benchmarking LLM agents for vulnerability research (07/22/2025)
- Vulnerable Ollama Instances – Is Your Ollama Server Publicly Exposed? (07/10/2025)
- AI Agents for application security testing (06/26/2025)
This benchmark confirms that while AI agents show promise for vulnerability detection, significant challenges remain in precision and recall. Enhanced prompting strategies and system designs will be vital to fully harness LLMs for security analysis.


